Gần đây thấy khá nhiều ae hỏi về vấn đề index (lập chỉ mục) trên GSC. Sẵn hướng dẫn một số bạn thì mình tổng hợp lại vài kinh nghiệm sửa lỗi cho ae luôn.
Trên GSC mục Page indexing được chia làm 2 nhóm chính: Indexed (xanh) và Not indexed (xám).
Trước tiên bạn cần hiểu cơ chế cách thức hoạt động của Gồ đối với dữ liệu các website:
- Discover > Crawl > Index > Serve (Rank).
- Phát hiện > Thu thập (quét) > Lập chỉ mục > Phân phát (Xếp hạng).
Tiếp theo bạn cần nắm sơ qua về lý thuyết của 2 nhóm Indexed và Not indexed.
1. Indexed (đã lập chỉ mục)
Ý nghĩa:
- Là các URL đã được Gồ thu thập thông tin, đã đưa vào kho chỉ mục, có khả năng hiển thị trên kết quả tìm kiếm SERP.
- Gồ đánh giá trang có đủ chất lượng hoặc không có lỗi kỹ thuật nghiêm trọng.
- Số trang được lập chỉ mục càng cao (so với tổng số trang hợp lệ) càng tốt. Chứng tỏ web hoạt động tốt trong mắt Gồ.
Các nguyên tắc tối ưu chính:
- Kiểm tra: Robots.txt, noindex, canonical: tránh chặn Gồ lập chỉ mục nhầm.
- Sitemap: tạo, cập nhật XML sitemap, submit lên GSC để giúp Gồ hiểu website rõ hơn.
- Đảm bảo trang ko có lỗi kỹ thuật, có nội dung chất lượng, đáp ứng intent của người dùng.
- Inlink: xây dựng liên kết nội bộ hợp lý, giúp Gồ bot dễ thu thập thông tin.
2. Not indexed (chưa được lập chỉ mục)
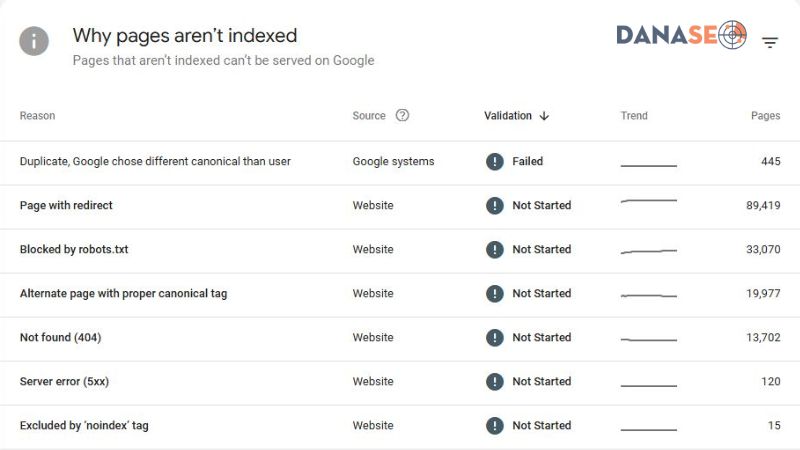
Là các URL KHÔNG được lập chỉ mục bởi Gồ. Vì nhiều lý do, chi tiết từng lý do ở phần “Why pages aren’t indexed?” (Lý do trang không được lập chỉ mục).
Nguyên tắc xử lý chung cho nhóm Not indexed
1. Đi vào từng nhóm nguyên nhân cụ thể, rà từng URL xem thực tế URL đó thuộc loại nào, có nên cho index hay không, bị vấn đề gốc (root cause) gì mà ko được index bởi nhóm lý do này.
2. Xử lý nguyên nhân gốc (nếu cần). Vd: nếu vấn đề đó là chủ đích (chặn index, thao tác redirect, găn canonical…) thì đừng làm gì cả. Nếu trang đó ko cần index thì kệ bà nó, hoặc có thể chặn luôn trên robots. Nếu trang cần index thì tìm xem tại sao nó chưa index để xử, rồi ép index lại cho nó, GSC inspect và các tool ép bên thứ 3.
3. Validate (Xác thực) cho nhóm vấn đề đó sau khi done bước 2, để Gồ crawl và đọc lại và cập nhật kết quả mới nhất.
Chi tiết từng nguyên nhân Not indexed và hướng xử lý
1. Discovered – Currently Not Indexed (Đã phát hiện thấy – hiện chưa được lập chỉ mục)
* Gồ đã thấy URL nhưng chưa thu thập dữ liệu (Crawl), thường do website có quá nhiều trang hoặc crawl budget bị giới hạn.
Check robots, sitemap, thẻ noindex, Crawl stats có bất thường?
2. Crawled – Currently Not Indexed (Đã thu thập dữ liệu – hiện chưa được lập chỉ mục)
* Gồ đã thu thập nhưng chưa lập chỉ mục do nội dung yếu hoặc bị coi là không quan trọng.
Kiểm tra chất lượng nội dung, lỗi kỹ thuật, thin, trùng lặp, ăn thịt, trải nghiệm kém…
3. Excluded by Noindex Tag (Bị loại trừ bởi thẻ ‘noindex’)
* URL có gắn thẻ noindex nên không được Gồ lập chỉ mục.
Check lại xem có chủ đích gắn thẻ noindex ko, nếu đúng thì kệ, nếu ko thì gỡ ra để đc index.
4. Blocked by Robots.txt (Bị chặn bằng tệp robots.txt)
* Hiện bị chặn bằng lệnh Disallow trên file Robots.
Check lại xem có chủ đích chặn robots, nếu đúng thì kệ, nếu ko thì bỏ chặn để đc index.
5. Duplicate, Google chose different canonical than user (Trang trùng lặp, Google đã chọn một trang chính tắc khác với lựa chọn của người dùng)
* URL này có khai báo canonical, nhưng Gồ chọn URL khác phù hợp hơn để làm chính tắc và index nó chứ ko index URL này. Thường xảy ra khi bạn cố tính set canonical chỉ để thao túng thứ hạng chứ ko phải vì nội dung thực sự tương đồng. Đôi khi chỉ là lỗi kỹ thuật trùng lặp về có và không có dấu “/” ở cuối URL.
Check xem đã đồng nhất có hoặc không dấu “/” cuối URL, đảm bảo các URL khác nhau thì tách biệt về mặt nội dung và set thẻ canonical chuẩn.
6. Duplicate Without User-Selected Canonical (Trang trùng lặp, người dùng chưa chọn trang chính tắc)
* URL bị đánh giá là trùng lặp (duplicate) nhưng chưa có thẻ canonical.
Thường bị ở mấy trang /feed/, /page/ nếu chưa có thẻ canonical về trang chính. Gắn canonical chuẩn và (hoặc) chặn luôn trên robots nếu ko muốn crawl/index.
7. Alternate page with proper canonical tag
(Trang thay thế có thẻ chính tắc thích hợp)
* URL có trỏ canonical về url khác nên ko đc index.
> Check xem có đúng ý định redirect ko, đúng thì oke, ko thì chỉnh lại.
8. Page with Redirect (Trang có lệnh chuyển hướng)
* URL đang bị redirect qua url khác nên ko đc index.
Check xem có đúng ý định redirect ko, đúng thì kệ, ko thì gỡ hoặc chỉnh lại.
9. Redirect error (Lỗi chuyển hướng)
* Có thể các lỗi: chuyển hướng chuỗi và vòng lặp, chuyển hướng đến URL không hợp lệ.
Gỡ chuyển hướng vòng lặp, chuyển hướng đến đúng URL hợp lệ.
10. Server error (5xx) (Lỗi máy chủ (5xx))
* URL bị lỗi Server 5xx nên ko đc index.
Xử lý lỗi Server, đảm bảo code 200 rồi push index lại.
11. Not Found (404) (Không tìm thấy (404))
* URL ko tồn tại, mã code 404.
Check xem URL này còn ko, 404 là đúng chủ đích chưa. Nếu trang còn dùng thì phải chỉnh về 200. Nếu ko dùng thì kệ, hoặc chặn robots.
12. Soft 404 (404 mềm)
* URL ko có nội dung chính, chỉ có header/sidebar/footer…, trang sản phẩm trống, hoặc trang danh mục ko có sản phẩm nào. Tức lẽ ra trang này nên là code 404 nhưng hiện tại đang 200.
Xem trang còn dùng ko để bổ sung nội dung, nếu ko dùng thì trả về 404, chặn robots khỏi crawl.
Ngoài ra còn 1 nhóm Indexed nhưng lại bị chặn trên robots:
- Indexed, though blocked by robots.txt
- (Đã lập chỉ mục mặc dù bị chặn bởi robots.txt)
* Gồ đã lập chỉ mục, đã đưa vào nhóm Indexed (xanh) mặc dù nhóm này đang được set lệnh chặn trên file robots.
Check xem chặn đúng ý định chưa để điều chỉnh. Nếu đúng là cần chặn thì check xem thực tế có đang index trên SERP không bằng site:URL để deindex, gửi lệnh Removals cho nhóm URL này để Gồ cập nhật lại nhóm Indexed. Ngược lại nếu ko cần chặn thì phải tắt Disallow để Gồ crawl bình thường.
Sau khi rà sửa từng nhóm lỗi xong thì nhớ thực hiện bước 3 theo nguyên tắc xử lý chung mình có nói ở trên: Validate (Xác thực) để Gồ đọc và cập nhật lại kết quả mới.
Bạn cần hiểu là nhóm Not indexed (xám) luôn tồn tại đối với bất kỳ website nào, chỉ khác nhau về số lượng thôi. Và thực ra mớ này là Thông báo (Notices) chứ ko hoàn toàn là Lỗi (Errors) nên đừng kỳ vọng phải xử lý hết tụi nó về 0.
Thêm nữa, tùy vào loại website, cấu trúc link và các nhóm URL ở từng giai đoạn khác nhau mà số lượng Indexed (xanh) và Not indexed (xám) có sự tăng giảm tương ứng. Không phải lúc nào index nhiều cũng là tốt, thường là ngược lại.
Vì vậy bạn cần quay lại tìm hiểu thật kỹ Cơ chế Gồ hoạt động, cách nó thu thập và lập chỉ mục các nội dung website ra sao. Sau đó bạn phải thực sự hiểu rõ các nhóm URL trên website của mình, loại nào nên index loại nào không.
Chỉ khi đó bạn mới có thể điều khiển được và kiểm soát chính xác việc index các URL trên website của mình.
Một lưu ý là bộ dữ liệu này của GSC lưu trữ cho các website không được cập nhật thường xuyên, thời gian cập nhật lại khá lâu (tùy Crawl budget từng web). Vì vậy sau khi fix xong bạn phải submit và kiên nhẫn đợi, thường xuyên kiểm tra, điều chỉnh rồi submit lại nhiều đợt. Có thể submit lại Sitemap và fetch lại robots khi có sự thay đổi để nhắc Gồ vào đọc nhanh hơn.
Hi vọng vài kinh nghiệm nhỏ giúp ae hiểu và xử lý tốt hơn vấn đề index trên website. Cảm ơn ae.
Nguồn tham khảo:
- Bá An - Nhóm Facebook "Cộng đồng SEO" - https://www.facebook.com/groups/hoidapseovincentdo/posts/3865312987068761/ - Tài liệu "Báo cáo Lập chỉ mục trang" của Google - https://support.google.com/webmasters/answer/7440203



